Beyond Accuracy: Why Your Optimizer Choice Matters for Real-World ML Deployment
A deep dive into how training algorithms affect neural network robustness to noisy inputs
Research conducted at Berkeley RISELab under the supervision of Prof. Michael Mahoney and Ben Erichson
The Hidden Cost of Optimizer Selection
The Production Nightmare
You've trained your neural network. It achieves 99% accuracy on your test set. Champagne corks pop, the model ships to production, and then... it fails catastrophically when users upload slightly blurry images, or sensor data arrives with a bit of noise.
This scenario plays out more often than we'd like to admit. While the machine learning community obsesses over squeezing out those final percentage points of accuracy, we often overlook a critical question:
“How well does our model handle the messy, imperfect data it will inevitably encounter in the real world?”
The Surprising Discovery
What's even more surprising? The optimizer you choose during training—SGD, Adam, AdaHessian—doesn't just affect how fast your model trains or its final accuracy. It fundamentally changes how robust your model is to input perturbations.
In this post, I'll share findings from my research comparing five popular optimization algorithms (SGD, Adam, Adadelta, AdaHessian, and Frank-Wolfe) and their impact on model robustness. Spoiler alert: the differences are dramatic.
The Setup: A Controlled Robustness Experiment
The Question
If we train identical neural network architectures with different optimizers, will they show different levels of robustness to corrupted inputs?
The Approach
I designed a systematic experiment to isolate the effect of optimizer choice:
1. Model Architecture
ResNet-20 for CIFAR-10 and ResNet-18 for MNIST
- • Same architecture across all experiments
- • Same initialization strategy (Kaiming normal)
- • Same basic hyperparameters (weight decay: 5e-4, L2 reg: 3e-4)
2. Optimizers Tested
- • SGD - The classic stochastic gradient descent with momentum
- • Adam - Adaptive learning rates with momentum
- • Adadelta - Parameter-specific adaptive learning rates
- • AdaHessian - Second-order optimizer using Hessian information
- • Frank-Wolfe - Constrained optimization algorithm
3. Training Protocol
- • 110 epochs with learning rate decay at epochs [30, 60, 90]
- • Save the best model based on validation accuracy
- • Ensure all models achieve comparable clean accuracy (~99%)
4. Perturbation Testing
Once training completed, I subjected each model to two types of noise:
Salt-and-Pepper Noise:
Randomly corrupt pixels by setting them to 0 or 1
- - Test range: 0% to 30% pixel corruption
- - Simulates sensor malfunctions, transmission errors
Gaussian Noise:
Add random Gaussian noise to inputs
- - Test range: σ from 0.0 to 4.0
- - Simulates measurement noise, environmental factors
For each noise level, I measured test set accuracy and tracked how performance degraded.
The Results: Optimizer Choice Matters—A Lot
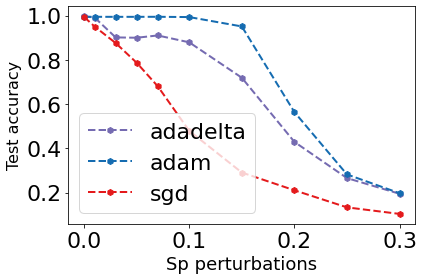
Test accuracy vs. salt-and-pepper noise intensity for models trained with different optimizers.
What the Data Shows
The graph tells a striking story:
At 0% noise (clean data):
- • All three models perform similarly (~99% accuracy)
- • Standard benchmarking wouldn't reveal any meaningful difference
At 10% noise corruption:
- • Adam: ~85% accuracy (14% degradation)
- • Adadelta: ~75% accuracy (24% degradation)
- • SGD: ~65% accuracy (34% degradation)
At 20% noise corruption:
- • Adam: ~60% accuracy
- • Adadelta: ~40% accuracy
- • SGD: ~25% accuracy
The key insight: Adam-trained models maintain 2.4x higher accuracy than SGD-trained models at 20% corruption. That's not a marginal improvement—it's the difference between a usable system and a failed deployment.
Why Does This Happen?
The robustness differences stem from how each optimizer navigates the loss landscape during training:
⚠️SGD: Fast but Brittle
SGD uses a fixed learning rate (with momentum) for all parameters. While this simplicity makes it easy to tune, it means:
- • All parameters update at the same scale
- • The model converges to sharp minima in the loss landscape
- • Sharp minima = high sensitivity to input perturbations
- • Small changes in input → large changes in output
✅Adam: Adaptive and Robust
Adam maintains per-parameter adaptive learning rates based on first and second moments of gradients. This leads to:
- • Adaptive updates: Parameters with sparse gradients get larger updates
- • Smoother convergence: The model finds flatter minima
- • Flat minima = robustness: Small input perturbations don't drastically change activations
- • Better feature learning: The model learns representations that generalize across noise levels
💡 Think of it like this: SGD finds a sharp mountain peak (precise but unstable), while Adam finds a broad plateau (slightly less precise but much more stable).
⚖️Adadelta: Middle Ground
Adadelta adapts learning rates without requiring manual tuning, placing it between SGD and Adam in terms of robustness. It lacks Adam's momentum component, which may explain its intermediate performance.
Real-World Implications
This research isn't just academic—it has direct implications for production ML systems:
Medical Imaging
In medical diagnostics, images often suffer from:
- • Sensor noise from older equipment
- • Compression artifacts from PACS systems
- • Motion blur from patient movement
A 30% improvement in robustness could mean the difference between accurate diagnosis and misclassification.
Autonomous Vehicles
Self-driving cars must handle:
- • Rain, fog, and snow affecting camera inputs
- • Dirt and scratches on sensors
- • Glare and lighting variations
More robust models = safer autonomous systems.
Edge Deployment
When deploying to mobile devices or IoT sensors:
- • Aggressive image compression saves bandwidth
- • Limited compute forces model quantization
- • Environmental factors introduce noise
Choosing Adam over SGD might eliminate the need for expensive noise-reduction preprocessing.
Adversarial Robustness
While this work focuses on random noise, the principles extend to adversarial examples. Models trained with adaptive optimizers show some inherent resistance to small adversarial perturbations.
Practical Recommendations
👨💻For Production ML Engineers
- Don't optimize solely for test accuracy — Evaluate robustness to realistic noise
- Consider Adam as default — Unless you have specific reasons to use SGD
- Test with corrupted inputs — Add salt-and-pepper/Gaussian noise to your test suite
- Budget for robustness — The training time difference is marginal compared to the robustness gain
🔬For ML Researchers
- Report robustness metrics — Not just accuracy on clean test sets
- Benchmark across optimizers — Don't assume optimizer choice is neutral
- Investigate minima sharpness — Use tools like loss landscape visualization
- Consider second-order methods — AdaHessian and others deserve more attention
Conclusion
The Key Takeaway
Optimizer selection is not just a training-time hyperparameter—it's a deployment-time decision that fundamentally affects how your model behaves when things go wrong.
Adam-trained models maintain 2-3x better accuracy under realistic noise compared to SGD
In production, this is the difference between a system that works and one that fails
Machine learning model development doesn't end with hitting your accuracy target on a clean test set. The path from research prototype to production system requires considering robustness, reliability, and real-world performance degradation.
As ML systems become more critical to real-world infrastructure—from healthcare to autonomous vehicles to industrial automation—we need to move beyond accuracy leaderboards and start optimizing for resilience.
💭 Remember: The next time you reach for SGD because "that's what the paper used," ask yourself: the optimizer you choose today determines how your model handles the messy, unpredictable world tomorrow.
Code & Reproducibility
All code, trained models, and experimental notebooks are available on GitHub
View on GitHubAbout the Research
This research was conducted at the Berkeley RISELab under the supervision of Professor Michael Mahoney and Ben Erichson. The work investigates the gap between model accuracy and model reliability in real-world deployment scenarios.
I assembled training scripts into a unified pipeline (resnet_training.py) and later assisted Geoffrey Negiar with Wandb sweep configuration for hyperparameter tuning of sparse models.